
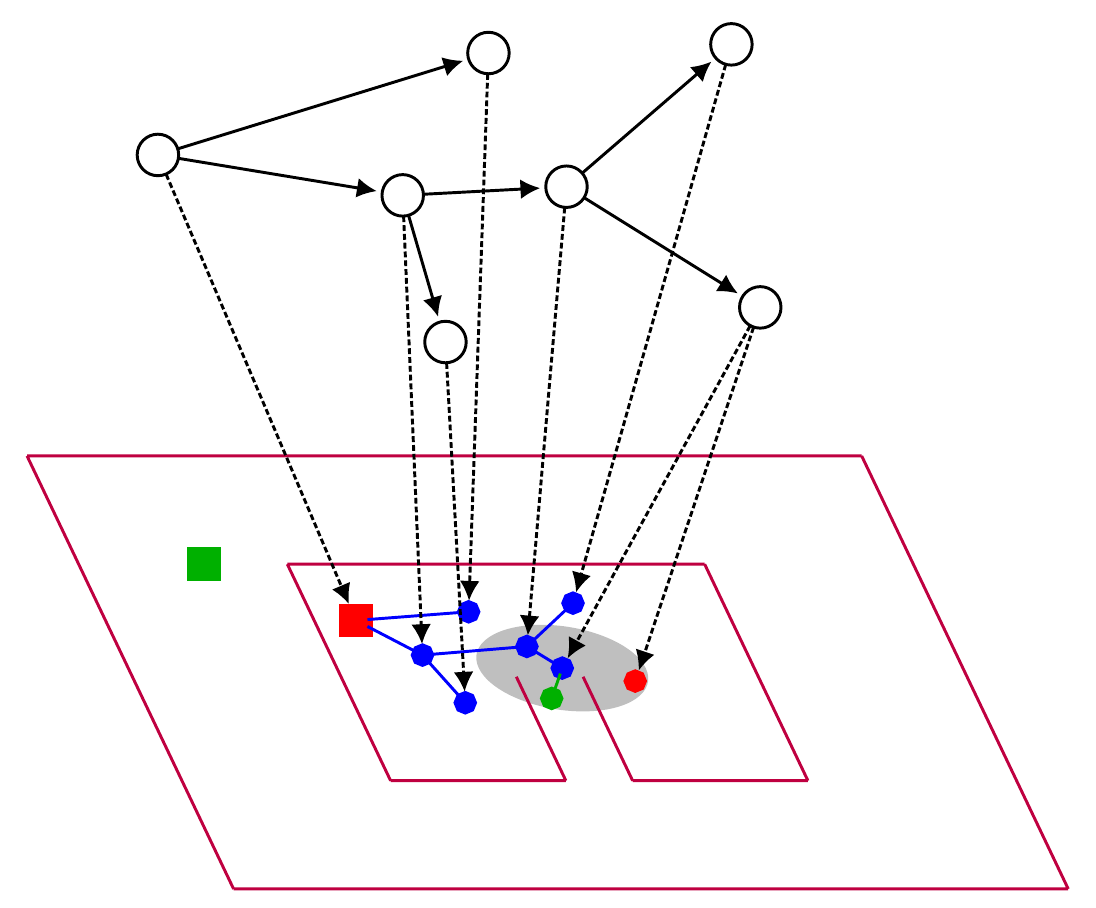
October 2018Deep sequential models for sampling-based planning
conferenceInternational Conference on Intelligent Robots (IROS)
We demonstrate how a sequence model and a sampling-based planner can influence each other to produce efficient plans and how such a model can automatically learn to take advantage of observations of the environment.

July 2017Temporal Grounding Graphs for Language Understanding with Accrued Visual-Linguistic Context
conferenceInternational Joint Conference on Artificial Intelligence (JCAI)
A robot’s ability to understand or ground natural language instructions is fundamentally tied to its knowledge about the surrounding world. We present an approach to grounding natural language utterances in the context of factual information gathered through natural-language interactions and past visual observations.

October 2016Saying what you're looking for: Linguistics meets video search
journalTransactions on Pattern Analysis and Machine Intelligence (PAMI)
We present an approach to searching large video corpora for clips which depict a natural-language query in the form of a sentence. Compositional semantics is used to encode subtle meaning differences lost in other approaches, such as the difference between two sentences which have identical words but entirely different meaning: The person rode the horse versus The horse rode the person. Given a sentential query and a natural-language parser, we produce a score indicating how well a video clip depicts that sentence for each clip in a corpus and return a ranked list of clips. Two fundamental problems are addressed simultaneously: detecting and tracking objects, and recognizing whether those tracks depict the query. Because both tracking and object detection are unreliable, our approach uses the sentential query to focus the tracker on the relevant participants and ensures that the resulting tracks are described by the sentential query. While most earlier work was limited to single-word queries which correspond to either verbs or nouns, we search for complex queries which contain multiple phrases, such as prepositional phrases, and modifiers, such as adverbs. We demonstrate this approach by searching for 2,627 naturally elicited sentential queries in 10 Hollywood movies.
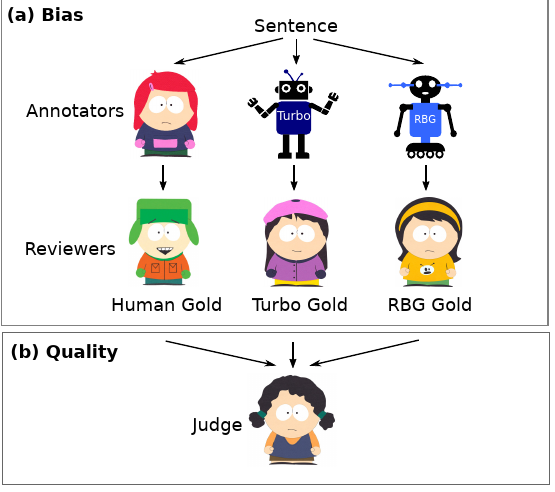
September 2016Anchoring and Agreement in Syntactic Annotations
conference, oralEmpirical Methods in Natural Language Processing (EMNLP)
We present a study on two key characteristics of human syntactic annotations: anchoring and agreement. Anchoring is a well known cognitive bias in human decision making, where judgments are drawn towards preexisting values. We study the influence of anchoring on a standard approach to creation of syntactic resources where syntactic annotations are obtained via human editing of tagger and parser output. Our experiments demonstrate a clear anchoring effect and reveal unwanted consequences, including overestimation of parsing performance and lower quality of annotations in comparison with humanbased annotations. Using sentences from the Penn Treebank WSJ, we also report systematically obtained inter-annotator agreement estimates for English dependency parsing. Our agreement results control for parser bias, and are consequential in that they are on par with state of the art parsing performance for English newswire. We discuss the impact of our findings on strategies for future annotation efforts and parser evaluations.
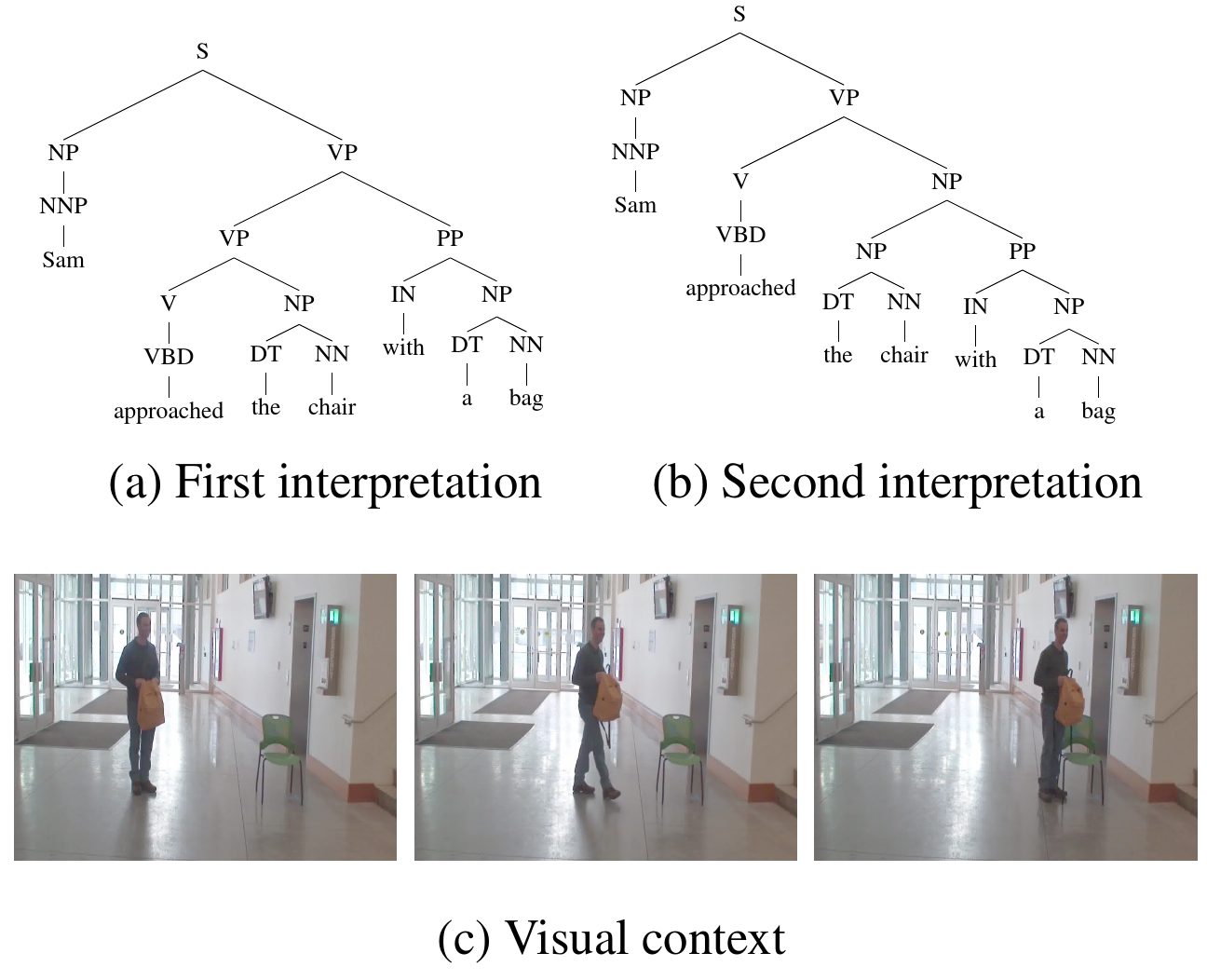
September 2015Do You See What I Mean? Visual Resolution of Linguistic Ambiguities
conference, oralEmpirical Methods in Natural Language Processing (EMNLP)
Understanding language goes hand in hand with the ability to integrate complex contextual information obtained via perception. In this work, we present a novel task for grounded language understanding: disambiguating a sentence given a visual scene which depicts one of the possible interpretations of that sentence. To this end, we introduce a new multimodal corpus containing ambiguous sentences, representing a wide range of syntactic, semantic and discourse ambiguities, coupled with videos that visualize the different interpretations for each sentence. We address this task by extending a vision model which determines if a sentence is depicted by a video. We demonstrate how such a model can be adjusted to recognize different interpretations of the same underlying sentence, allowing to disambiguate sentences in a unified fashion across the different ambiguity types.
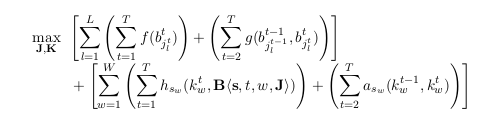
April 2015A Compositional Framework for Grounding Language Inference, Generation, and Acquisition in Video
journalJournal of Artificial Intelligence Research (JAIR)
We present an approach to simultaneously reasoning about a video clip and an entire natural-language sentence. The compositional nature of language is exploited to construct models which represent the meanings of entire sentences composed out of the meanings of the words in those sentences mediated by a grammar that encodes the predicate-argument relations. We demonstrate that these models faithfully represent the meanings of sentences and are sensitive to how the roles played by participants (nouns), their characteristics (adjectives), the actions performed (verbs), the manner of such actions (adverbs), and changing spatial relations between participants (prepositions) affect the meaning of a sentence and how it is grounded in video.
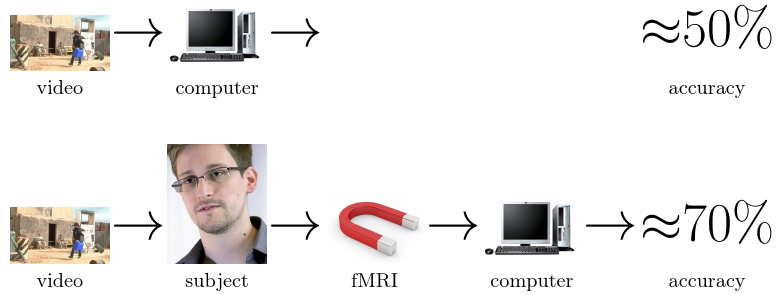
September 2014Seeing is Worse than Believing: Reading People’s Minds Better than Computer-Vision Methods Recognize Actions
conferenceEuropean Conference on Computer Vision (ECCV)
We had human subjects perform a one-out-of-six class action recognition task from video stimuli while undergoing functional magnetic resonance imaging (fMRI). Support-vector machines (SVMs) were trained on the recovered brain scans to classify actions observed during imaging, yielding average classification accuracy of 69.73% when tested on scans from the same subject and of 34.80% when tested on scans from different subjects. An apples-to-apples comparison was performed with all publicly available software that implements state-of-the-art action recognition on the same video corpus with the same cross-validation regimen and same partitioning into training and test sets, yielding classification accuracies between 31.25% and 52.34%. This indicates that one can read people’s minds better than state-of-the-art computer-vision methods can perform action recognition.
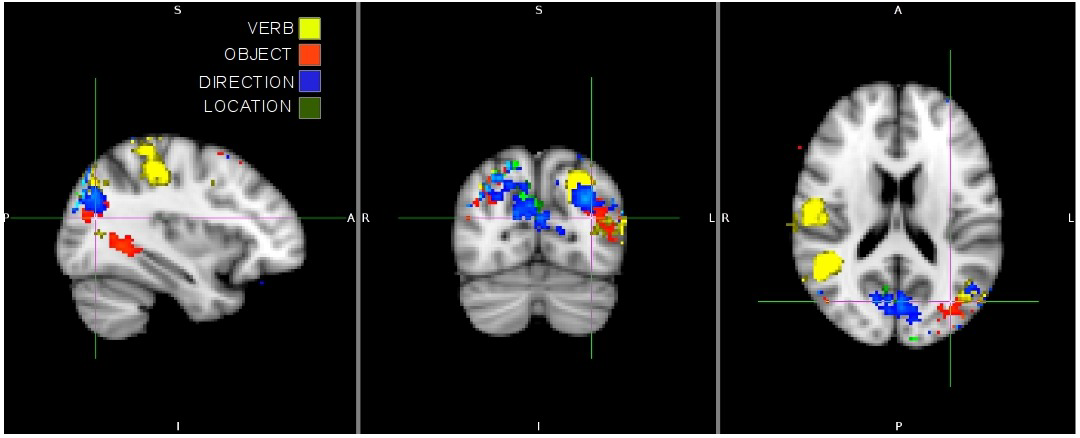
June 2014The compositional nature of verb and argument representations in the human brain
technical reportarxiv
We seek to understand the compositional nature of representations in the human brain. Subjects were shown videos of humans interacting with objects, and descriptions of those videos were recovered by identifying thoughts from fMRI activation patterns. Leading up to this result, we demonstrate the novel ability to decode thoughts corresponding to one of six verbs. Robustness of these results is demonstrated by replication at two different sites, and by preliminary work indicating the commonality of neural representations for verbs across subjects. We next demonstrate the ability to decode thoughts of multiple entities---the class of an object and the identity of an actor---simultaneously. These novel abilities allow us to show that the neural representation for argument structure may be compositional by decoding a complex thought composed of an actor, a verb, a direction, and an object.

June 2014Seeing What You're Told: Sentence-Guided Activity Recognition In Video
conferenceIEEE Conference on Computer Vision and Pattern Recognition (CVPR)
We present a system that demonstrates how the compositional structure of events, in concert with the compositional structure of language, provide a mechanism for multi-modal integration between vision and language. We show how the roles played by participants (nouns), their characteristics (adjectives), the actions performed (verbs), the manner of such actions (adverbs), and changing spatial relations between participants (prepositions) in the form of whole sentential descriptions mediated by a grammar, guides the activity-recognition process.


December 2012Simultaneous object detection, tracking, and event recognition
journal, oral at associated conference (14/38, 37%)Advances in Cognitive Systems (ACS)
Instead of recognizing hammering by detecting the motion of a hammer, we simultaneously search for hammering and the hammer, your knowledge about the event helps you recognize that event. By combining all three (object detection, tracking and event recognition) into one cost function they are seamlessly integrated and top-down information can influence bottom-up visual processing and vice-versa.

December 2012Seeing unseeability to see the unseeable
journal, oral at associated conference (14/38, 37%)Advances in Cognitive Systems (ACS)
There are many things you don't need to look at in order to understand or describe, for example you might see a rooftop and by virtue of the fact that it isn't speeding toward the ground you know there is a wall supporting it. Someone might also tell you, "Hey, there's a window over there by the door". This brings up four questions this paper addresses: "how do you infer knowledge from physical constraints of the world?", "how confident are you that what you're seeing is real?", "what can you do to raise that confidence?", and "how do you describe what you're seeing?".

August 2012Video in sentences out
conference, oral (24/304, 8%)Conference on Uncertainty In Artificial Intelligence (UAI)
Recognizing actions in videos and putting them in context by recognizing and tracking the participants and generating rich sentences that describe the action, its manner, the participants, and their changing spatial relationships. For the sample image we generate "The person slowly arrived from the right" and "The person slowly went leftward."

April 2012Large-Scale Automatic Labeling of Video Events with Verbs Based on Event-Participant Interaction
technical reportCoRR (arXiv:1204.3616)
We present an approach to labeling short video clips with English verbs as event descriptions. A key distinguishing aspect of this work is that it labels videos with verbs that describe the spatiotemporal interaction between event participants, humans and objects interacting with each other, abstracting away all object-class information and fine-grained image characteristics, and relying solely on the coarse-grained motion of the event participants. We apply our approach to a large set of 22 distinct verb classes and a corpus of 2,584 videos, yielding two surprising outcomes. First, a classification accuracy of greater than 70% on a 1-out-of-22 labeling task and greater than 85% on a variety of 1-out-of-10 subsets of this labeling task is independent of the choice of which of two different time-series classifiers we employ. Second, we achieve this level of accuracy using a highly impoverished intermediate representation consisting solely of the bounding boxes of one or two event participants as a function of time. This indicates that successful event recognition depends more on the choice of appropriate features that characterize the linguistic invariants of the event classes than on the particular classifier algorithms.

May 2011A visual language model for estimating object pose and structure in a generative visual domain
conference, oral (982/2004, 49%)IEEE International Conference on Robotics and Automation (ICRA)
Understanding and manipulating complex scenes through their components, using a visual language model which encodes physical constraints, such as "something must be supported otherwise it will fall" and the 3D affordances of parts which allow them to be assembled to form entire objects.

May 2010Learning physically-instantiated game play through visual observation
conference, oral (856/2062, 42%)IEEE International Conference on Robotics and Automation (ICRA)
An approach to learning complex rules of social interaction by observing real agents, either robotic or human, in the real world and then using that knowledge to drive futher iteraction with them.