This is woefully out of date. For now, see my publications page for more info.
My research sits at the intersection between artificial intelligence, computer vision, linguistics, robotics, and cognitive science. Broadly I investigate reasoning about the world through cognition grounded in vision & robotics and mediated by language in both humans and machines.

Combining language and vision to recognize events in videos, describe those events with natural English sentences, and search for complex events in large video corpora given sentential queries.
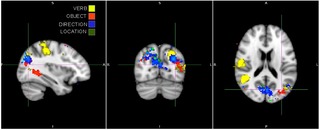
Reading minds to understand the neural basis of linguistic theories. Subjects are shown videos and their minds are read to recover different aspects of those videos. For example to recover who the actor was, what that actor did, what implement did they use, and where in the field of view was the action carried out.

Recognizing the part-by-part composition of a complex structure requires reasoning about occlusion and physics in 3D. We combine this with the ability to robotically manipulate such structures, to generate and understand sentences describing such structures, and to plan the actions needed to explore and understand such structures.

Games are microcosms in which we explore how robots can learn rules of social interaction, how they communicate knowledge between each other and humans, and how acquired knowledge can be used to manipulate the world.