Understanding the neural representation of language will help develop relevant linguistic theories and good representations for AI systems. We explore two questions: how does compositionality work in the brain and are representations for different concepts, such as verbs and nouns, independent from each other?
We answer these questions by reading subject's minds while in an MRI machine. Subjects are shown videos and asked to think about the events occurring in those videos. Their brains are scanned and the attributes of the videos are recovered. By recovering different concepts we can elucidate how those concepts are represented in the brain.
Videos for this experiment are constructed compositionally, we decide on a number of axes of variation, for example a number of verbs, objects, actors and direction/locations, and film one or more videos for each combination of each axis of variation.
We train a classifier (linear SVM after dimensionality reduction and various fMRI-related data cleanup operations) on the fMRI scan data and recover the subject's thoughts.
With this technique we present the first experiment which recovers thoughts of verbs and the first experiment which recovers a complex thought compositionally piece-by-piece. Further, we show that the representations of verbs and nouns are independent from each other, at least as at the granularity achievable with current fMRI techniques. In other words, a classifier does no better on verbs and nouns simultaneously than it does on each independently.
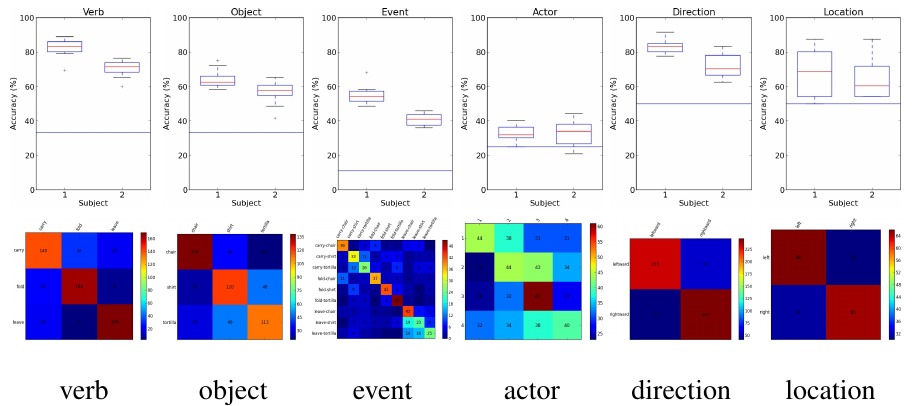
In the above image we show classification performance for two subjects on 8 runs (round-robin cross validation) of 72 images. In this experiment there are 3 verbs (carry, leave, and fold), 3 objects (tortilla, shirt, chair), 2 directions/locations (left/right). The box plots show the variance in classifier performance on each of the 8 runs. The red lines show chance performance. Event is a classifier that simultaneously recovers the verb and the object. Its performance is essentially equivalent to recovering them independently from each other, \(0.8212 \times 0.6441 = 0.5289 \approx 0.5538\). This provides evidence that the representation of verbs and nouns are independent.
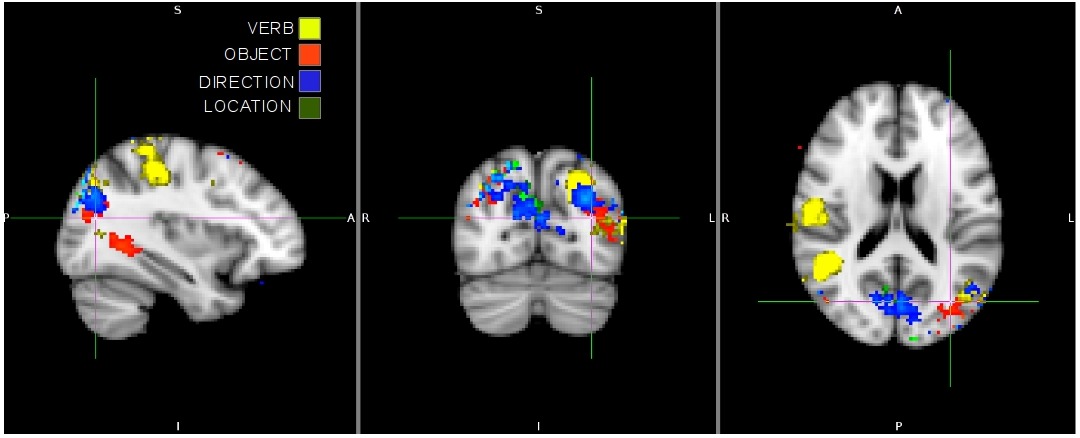
The above image plots regions of the which lead to high classifier performance. Different regions are relevant to different concepts. Verbs classification performance is due to the motor cortex, objects are classified using the temporal lobe and V3/V4, while direction and location are lower down in the visual cortex.
This work appeared in:
This work will appear in: